
A quite simple way to extract identical data using R (or RStudio) and an Excel file.
Creating A Dataset
(If you already have a dataset at hand, you may skip this section.)
This time, I will use an Excel file.
For instance, when I am writing posts related to newly learned English words from a book, I'm avoiding repeating the same words across the posts. To this end, I created an Excel file like the following image:
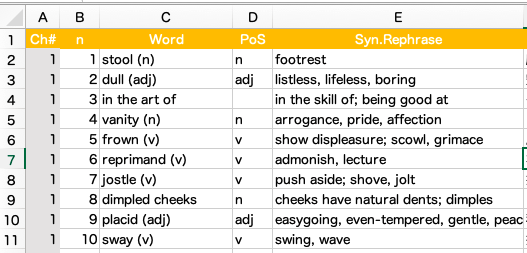
If you want to use a CSV file, you can select the format when you save the data (or when you rename it).
R's Script
R will extract the data we want by executing the following script.
library("openxlsx")
vocab_file <- read.xlsx("/Users/Emma/filename.xlsx") # storing the dataset into "vocab_file"
head(vocab_file) # checking the content if needed
library("dplyr")
duplicate <- vocab_file %>% # inside the "vocab_file,"
group_by(Word) %>% # in the column named "Word,"
filter(n()>1) # extract the rows that have identical value
duplicate <- duplicate[order(duplicate$Word),] # sorting the result in alphabetical order
duplicate # displaying the resultsLine 1 & 2: for CSV files, it's much easier to use read.csv() instead of read.xlsx(). In that case, skip the first line which loads the library "openxlsx".
Also, the path to the file should be changed in accordance with where your file is located.
Line 10th: I sorted the data with duplicate <- duplicate[order(duplicate$Word)] to organize the data. In this case, R reorders the English words in alphabetical order.
The result will be like the following:
If Any Duplicates
I intentionally inserted three duplicated lines in the file. So, R extracted those three and the original three as pairs.
> duplicate
# A tibble: 6 x 5
# Groups: Word [3]
`Ch#` n Word PoS Syn.Rephrase
<dbl> <chr> <chr> <chr> <chr>
1 1 8 dimpled cheeks n cheeks have natural dents; dimples
2 99 1 dimpled cheeks n cheeks have natural dents; dimples
3 4 14 impeccable (adj) adj flawless
4 100 14 impeccable (adj) adj flawless
5 5 5 initiate (n) n a person who has been initiated
6 100 5 initiate (n) n a person who has been initiatedIf this isn't sorted in alphabetical order, the pair may be distant one another.
If No Duplicates
> duplicate
# A tibble: 0 x 5
# Groups: Word [0]
# … with 6 variables: `Ch#` <dbl>, n <chr>, Word <chr>, PoS <chr>, Syn.Rephrase <chr>If there is no duplicates in the file, R shows comments like the above.
Learning The Basics of R
R for Data Science written by Dr. Hadley Wickhamis—currently Chief Scientist at RStudio—is a great resource to learn the basics of R. You can read it online (the above link) for free. There is also paperback and Kindle edition if you prefer them over online material. Highly recommended for beginners of Data Science or people self-teaching R.
